SQL의 역사
- 최초의 데이타 언어
- SEQUEL에 연유합니다.
- SEQUEL이란?
- -> 1974년, IBM 연구소에서 발표
- -> 실험적 관계 데이타베이스 시스템의 인터페이스인 'SYSTEM R' 인터페이스로 설계 구현(이 언어 처음 구현할 때)
표준 SQL
- 1986년, SQL 1
- 1992년, SQL 2
- 1999년, SQL 3
- 2003년,
- QL4, 객체 개념을 지원하는 기능 추가
현재
- 미국 표준 연구소(ANSI)와 국제 표준 기구(ISO)에서 관계 데이타베이스의 표준 언어로 채택
- 상용 DBMS인 IBM의 DB2와 SQL/DS의 데이타 언어로 사용하는 중 -> 제품 다르지만 형태 유사
- ORACLE, INFORMIX, SYBASE 등과 같은 다른 회사에서도 채택
SQL의 의미
- 일단 질의어란?? 질의어는 데이터베이스 시스템에게 원하는 데이터를 어떻게 가져올지, 어떻게 조작할지를 지시하는 명령어들의 집합, 자기 스스로 질문하고 알아서 하는 것임
- SQL은 "구조화 질의어"
- 종합 데이터베이스 언어 역할을 합니다.(데이타 정의어, 데이타 조작어, 데이타 제어어 기능 모두 제공)
- 단순히 검색만을 위한 데이터 질의어가 아닙니다.
SQL의 특징
- 관계 대수 + 확장된 투플 관계 해석을 기초
- 사용자 친화적인 인터페이스를 제공하는 고급, 비 절차적 데이타 언어 -> 효율적인 방법을 DBMS가 알아서 찾아서 씀
- SQL의 표준화
- -> 상용 RDBMS간의 전환이 용이
- -> 여러 관계 데이타베이스를 접근하는 데이타베이스 응용 프로그램의 작성을 지원
- 터미널을 통해 대화식 질의어로 사용
- 응용 프로그램에 삽입된 형태로 사용 가능
- 개개의 레코드 단위로 처리하기 보다는 레코드 집합 단위로 처리
- 선언적 언어(SQL 명령문에는 데이타 처리를 위한 접근 경로에 대한 명세가 불필요!!, 얻고자 하는 결과 선언 -> 알아서 결정)
- 관계 모델의 공식적이니 용어 대신 일반적인 용어를 사용(테이블, 행, 열)
SQL 데이타 정의문(DDL, 건물의 골격)
SQL DEFINITION 기능 - CREATE, ALTER, DROP
SQL 데이터 정의 언어(DDL)를 사용하여 테이블, 스키마, 도메인에 대한 정의를 할 수 있습니다.
데이터베이스의 구조를 정의하고 변경하는 명령어들
- 테이블: CREATE TABLE 구문을 사용하여 새로운 테이블을 생성하고, ALTER TABLE 구문을 사용하여 이미 존재하는 테이블의 구조를 변경할 수 있습니다.
- 스키마: CREATE SCHEMA 구문을 사용하여 새로운 스키마를 생성하고, ALTER SCHEMA 구문을 사용하여 스키마의 속성을 변경할 수 있습니다.
- 도메인: CREATE DOMAIN 구문을 사용하여 새로운 도메인을 생성하고, ALTER DOMAIN 구문을 사용하여 이미 존재하는 도메인의 속성을 변경할 수 있습니다. 도메인은 데이터 타입과 제약 조건을 결합하여 정의하는 개념으로, 테이블의 속성에 사용됩니다.
- 이러한 DDL 구문을 사용하여 데이터베이스에서 필요한 객체를 정의하고, 제약 조건을 설정하고, 데이터 타입을 지정할 수 있습니다.
먼저 데이타 정의문 살펴보기 전에 스키마와 카탈로그 알아보기
1. 스키마와 카탈로그(스키마 정의문)
스키마?
- 하나의 응용(사용자)에 속하는 테이블과 기타 구성요소 등의 그룹
- 포함 내용: 스키마 이름, 스키마를 소유하는 허가권자(DBA), 테이블, 뷰, 도메인, 기타 내용에 대한 기술자
- (EX) CREATE SKIMA UNIVERSITY AUTHORIZATION SHLEE;
- CREATE SKIMA 대신 CREATE DATABASE 명령문도 사용합니다.
카탈로그?
- SQL 시스템 내에서의 한 스키마 집합 = 데이타 베이스
- 스키마는 데이터베이스 내에서 서로 다른 데이터의 논리적인 구조를 구분하기 위해 사용되며, 하나의 데이터베이스에는 여러 개의 스키마가 존재
- 하나의 특별한 스키마인 Information schema를 포함합니다. -> 그 카탈로그에 있는 모든 스키마에 대한 정보 제공
2. 도메인 정의문
도메인?
- 데이터베이스에서 사용되는 데이터의 종류와 제약 조건을 정의하는 개체입니다.
- 도메인은 데이터베이스에서 사용될 수 있는 값의 범위를 제한하거나, 데이터의 형식을 지정하는 등의 제약을 설정할 수 있습니다.
- SQL이 지원하는 데이타 타입으로만 정의할 수 있습니다. / 일반 관계 데이터 모델은 사용자가 원하는 대로 가능
도메인 정의(CREATE)
CREATE DOMAIN domain_name data_type
[DEFAULT default_value]
[CHECK (condition)];
CREATE DOMAIN 도메인 이름 데이타 타입
DEFAULT 값이 없으면 들어갈 기정값
CHECK 제약조건
[ ]은 생략 가능하다는 말 !!!!!!도메인 변경과 삭제(ALTER, DROP)
//도메인 변경
ALTER DOMAIN 도메인_이름 <변경 내용>;
//도메인 삭제
DROP DOMAIN 도메인_이름 RESTRICT | CASCADE(옵션);- 옵션 중 RESTRICT는 다른 곳에서 이 도메인을 참조하고 있지 않을 때 삭제 가능합니다.
- 옵션 중 CASCADE는 이 도메인을 참조하고 있는 뷰나 제약조건도 같이 삭제!! 하지만 참조 열은 삭제되지 않고, 다른 데이타 타입으로 변경 !!!
데이타 타입
- 숫자
- INT(EGER), SMALLINT: 정수
- FLOAT(n), REAL, DOUBLE PRECISION: 실수
- DECIMAL(i,j), NUMERIC(i,j): 정형 숫자
2. 문자 스트링
- CHAR(n): 고정 길이 문자
- VARCHAR(n): 가변 길이 문자
3. 비트 스트링
- BIT(n), BIT VARYING(n)
4. 날짜
- DATE: YY-MM-DD
5. 시간
- TIME: hh:mm:ss
- TIMESTAMP: DATE와 TIME 포함
- TIMEINTERVAL: DATE, TIME, TIMESTAMP 포함
3. 기본 테이블의 생성(CREATE)
GROUP BY에 대한 조건문은 WHERE이 아니라 HAVING !!!!!!!!
테이블의 종류 : DDL로 만들어지는 것은 기본 테이블뿐이다~~
1. 기본 테이블(존재 !!)
- CREATE TABLE 문으로 만들어지는 테이블
- DBMS 화일로 생성되고 카탈로그에 저장(투플들이 DBMS에 의해 하나의 화일로 생성되고 저장)
- 기본 테이블에 있는 열은 CREATE TABLE문으로 명세된 열의 순서를 갖는다고 간주
- NOT NULL의 의미 속성값이 NULL이면 X
2. 가상 테이블(존재 X, 명령어 실행해서 기본 테이블로부터 변형해서 보여줌)
- CREATE VIEW 문으로 만들어지는 테이블
- 어떤 기본 테이블로부터 유도되어 만들어지는 테이블
- 독자적으로 존재 불가능
3. 임시 테이블(존재 X, 질의문에 의해서 기본테이블로부터 만들어짐)
- DDL로 만들어지는 것이 아니라 질의문 처리 과정의 중간 결과로 만들어지는 테이블
일반 형식(기본 테이블 정의하기 위한 정의문의 형식)
CREATE TABLE 테이블명 (
[열1명] [열1데이터형식] NOT NULL 기정값,
[열2명] [열2데이터형식],
...
[열n명] [열n데이터형식],
PRIMARY KEY ([기본키열명]), //기본키와 개체무결성제약조건명세
FOREIGN KEY ([외래키열명]) REFERENCES [참조테이블명]([참조테이블기본키열명])//외래키와 참조무결성제약조건명세
CHECK( ) //제약 조건 명세
);
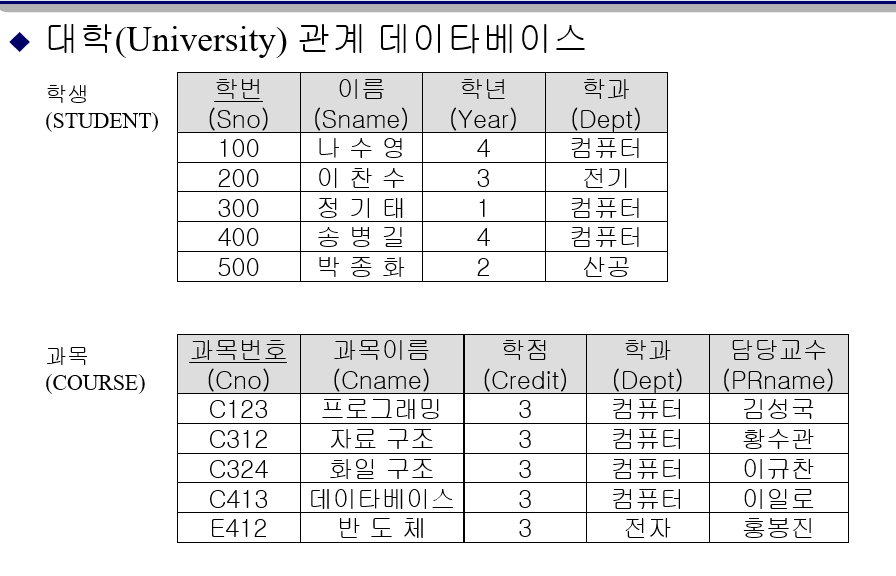
//1. 등록 테이블의 기본 테이블 생성하는 방법
CREATE TABLE ENROL(
Sno INT NOT NULL,
Cno CHAR(6) NOT NULL, //기본키들은 널값이 들어가면 안 됨
Grade INT,
PRIMARY KEY(Sno, Cno), //기본키 정의
FOREIGN KEY Sno REFERENCES STUDENT(Sno) //삭제->갱신 순서로 밑에 작성!!!
ON DELETE CASCADE //만약 참조하고 있던 STUDENT 테이블이 삭제되면 같이 삭제
ON UPDATE CASCADE, //만약 참조하고 있던 STUDENT 테이블이 업데이트되면 같이 업데이트
FOREIGN KEY Cno REFERENCES COURSE(Cno) // (Cno) 생략 가능!!
ON DELETE CASCADE //만약 참조하고 있던 COURSE 테이블이 삭제되면 같이 삭제
ON UPDATE CASCADE, //만약 참조하고 있던 COURSE 테이블이 업데이트되면 같이 업데이트
CHECK(Grade>=0 && Grade<=100)
); //제일 먼저 (); 해주고 그 안에 채우기
//2.학생 테이블의 기본 테이블 생성하는 방법
CREATE TABLE STUDENT
( Sno INT NOT NULL,
Sname CHAR(6),
Year INT,
Dept CHAR(10),
PRIMARY KEY(Sno),
CONSTRAINT year_check CHECK(Year>=1 AND Year<=4));
//3.과목 테이블의 기본 테이블 생성하는 방법
CREATE TABLE COURSE
( Cno CHAR(6) NOT NULL,
Cname CHAR(10),
Credit INT,
Dept CHAR(10),
PRname CHAR(6),
PRIMARY KEY(Cno));
CREATE TABLE ENROL
( Sno INT NOT NULL,
Cno CHAR(6) NOT NULL,
Grade CHAR(2),
Midterm INT,
Final INT,
PRIMARY KEY(Sno, Cno),
FOREIGN KEY(Sno) REFERENCES STUDENT(Sno)
ON DELETE CASCADE
ON UPDATE CASCADE,
FOREIGN KEY(Cno) REFERENCES COURSE(Cno)
ON DELETE CASCADE
ON UPDATE CASCADE,
CHECK(Grade>=0 AND Grade <=100));4. 기본 테이블의 제거와 변경(DROP, ALTER)
기본 테이블의 제거(뷰나 제약조건)
//기본 테이블 제거
DROP TABLE 테이블명 {RESTRICT | CASCADE};
DROP TABLE COURSE CASCADE;
//RESTRICT: 이 테이블을 참조하고있는 뷰나 제약조건이 있으면 실행 실패
//CASCADE: 이 테이블 참조하는 뷰나 제약조건도 모두 삭제
//-> 뷰는 기본 테이블을 참조하여 가상의 테이블을 생성하는 개념
//제약 조건은 테이블의 데이터 무결성을 지키기 위해 설정되는 규칙스키마 제거
//스키마 제거
DROP SCHEMA 스키마_이름 {RESTRICT | CASCADE};
DROP SKIMA UNIVERSITY CASCADE;
//CASCADE 옵션을 사용하여 스키마 내의 모든 객체를 함께 제거
//RESTRICT 옵션은 스키마가 공백인 경우에만 삭제 가능기본 테이블의 변경
1. 새로운 열의 첨가
2. 기존 열의 삭제
3. 기존 열에 대한 새로운 기정 값의 명세(DROP하거나 SET하거나)
ALTER TABLE ENROL ADD Final CHAR DEFAULT 'F';
ALTER TABLE ENROL DROP Grade CASCADE;
//위의 ALTER TABLE 명령어는 "ENROL" 테이블의 "Grade" 열의 기본값을 제거하는 명령어
ALTER TABLE ENROL ALTER Grade DROP DEFAULT;
ALTER TABLE ENROL ALTER Grade SET DEFAULT '0'; //"Grade" 열의 기본값을 0으로 셋팅
SQL 데이타 조작문(DML)
- 데이터베이스에 저장된 데이터를 조회, 삽입, 수정, 삭제하는 명령어들
- SELECT(검색), INSERT(삽입), DELETE(삭제), UPDATE(갱신)이 있다.
- 처리 대상은 기본 테이블이나 뷰
1. 데이타 검색
SELECT(검색해줘) , ,의 열을 FROM 테이블(로부터) WHERE ~(의 조건을 만족하는)
SELECT = 프로젝트, WHERE 조건식=셀렉트 관계대수와 비슷!!!
SELECT [열1, 열2, ...]
FROM 테이블명
WHERE 조건식;
//예를 들어, "students"라는 테이블에서 "name"과 "age"라는 두 개의 열을 조회하고
//"age"가 20살 이상인 데이터를 검색하는 SQL SELECT 문
SELECT name, age
FROM students
WHERE age >= 20;
SELECT Sname, Sno
FROM STUDENT
WHERE Dept='컴퓨터';
SELECT STUDENT.Sname, STUDENT.Sno
FROM STUDENT
WHERE STUDENT.Dept='컴퓨터';- 폐쇄 시스템: 테이블 처리 결과가 또 다시 테이블이 되는 시스템
- 중첩 질의문을 구성할 수 있는 이론적 기초
SQL과 이론적 관계 모델의 차이점
SQL에서 "중복 데이터"란, 테이블의 동일한 애트리뷰트 값들을 갖는 튜플들이 중복되어 존재하는 경우 -> 따라서 테이블이 튜플들의 집합이 아니다. 왜냐면 "집합"이란 중복되지 않아야 하는 것인데 같은 애트리뷰트에 중복되는 튜플이 존재할 수 있기 때문 !!! 따라서 기본키가 반드시 있어야 하는 것은 아니다.(기본키의 튜플들은 중복될 수 없음)
테이블의 한 컬럼(애트리뷰트)에서 같은 값을 가진 두 개 이상의 튜플이 중복되어 저장되는 상황
- 한 테이블 내에 똑같은 레코드(행) 중복 가능
- 기본 키를 반드시 가져야 하는 것은 아님
- 이론상 SQL의 테이블은 투플의 집합이 아님
- 같은 원소의 중복을 허용하는 다중 집합 또는 백이다. -> 집합(set)과 유사하지만, 원소의 중복을 허용하는 자료구조
- 중복을 제거하려면 DISTINCT 명세 -> 집합과 같은 결과 만듦(SELECT DISTINCT 가져올 열들)->열의 투플들 중복 제거 뚜렷한 !!!!!!
//일반적인 형식
SELECT [ALL|DISTINCT] 열_리스트
FROM 테이블_리스트
[WHERE 조건]
[GROUP BY 열 리스트
[HAVING 조건]]
[ORDERED BY 열_리스트 [ASC|DESC]];- SELECT: 데이터 검색할 때 반환할 열(애트리뷰트)의 리스트를 지정합니다. [ALL|DISTINCT] 옵션을 사용하여 중복된 값들을 모두 가져올지, 유일한 값들만 가져올지를 선택할 수 있습니다.
- FROM: 데이터를 검색할 테이블(릴레이션)의 리스트를 지정합니다.
- WHERE: 데이터를 검색할 때 적용할 조건을 지정합니다. 조건을 만족하는 행(튜플)들만을 검색합니다.
- GROUP BY: 특정 열(애트리뷰트)을 기준으로 데이터를 그룹화합니다. 그룹화된 데이터의 통계 정보를 얻거나, 그룹 단위로 데이터를 처리할 수 있습니다.
- HAVING: GROUP BY와 함께 사용되며, 그룹화된 데이터에 대한 조건을 지정합니다. 그룹 단위로 데이터를 필터링하고 싶을 때 사용합니다.
- ORDER BY: 검색 결과의 정렬 순서를 지정합니다. 열(애트리뷰트)의 리스트와 정렬 방향(ASC: 오름차순, DESC: 내림차순)을 지정할 수 있습니다.
2. 데이타 검색 예시(결과 테이블 무조건 써보기)
질의문-> SQL 검색문 기술(표현보고 식 나오게)-> 결과 테이블

(1) 검색 결과에 중복 레코드의 제거 DISTINCT
- 질의문: 학생 테이블에 어떤 학과들이 있는지 검색하라.
(2) 테이블의 열 전부를 검색하는 경우 *
- 질의문: 학생 테이블 전부를 검색하라.
(3) 조건 검색 WHERE
- 질의문: 학생 테이블에서 학과가 '컴퓨터'이고 학년이 4인 학생의 학번과 이름을 검색하라.
(4) 순서를 명세하는 검색 ORDERED BY 열 [DESC | ASC]
- 질의문: 등록 테이블에서 중간 성적이 90점 이상인 학생의 학번과 과목 번호를 검색하되 학번에 대해서는 내림차순으로, 또 같은 학번에 대해서는 과목 번호의 오름차순으로 검색하라.
(5) 산술식과 문자 스트링이 명세된 검색(이름 변경) 기존 이름 AS 바꿀 이름(별명 지정!!)
- 질의문: 등록 테이블에서 과목 번호가 'C312'인 중간 성적에 3점을 더한 점수를 '점수', ' 중간성적 ='이란 텍스트 내용을 '시험', 그리고 '학번'라는 열 이름으로 검색하라.
(6) 복수 테이블로부터의 검색(조인) - WHRER 절에 조인 명세
- 질의문: 과목 번호 'C413'에 등록한 학생의 이름, 학과, 성적을 검색하라.
(7) 자기 자신의 테이블에 조인하는 검색 - WHRER 절에 조인 명세
- 질의문: 같은 학과 학생들의 쌍으로 검색하라. 단 첫 번째 학번은 두 번째 학번보다 작게 하라.
(8) FROM 절에서 조인 명세(3가지 있음. ON 조건, USING 조인애트리뷰트, 자연 조인) -6번을 고쳐서 써라.
//WHERE 절에서의 조인과 FROM 절에서의 조인 명세를 할 수 있습니다.
//WHERE 절 같은 경우는
FROM 테이블명 별칭1, 테이블명 별칭2
WHERE 별칭1.조인 애트리뷰트 = 별칭2.조인 애트리뷰트
//FROM 절에서 조인 명세하면?
//FROM ~ JOIN ~ ON 조건
//1. 조인 애트리뷰트 이름이 달라도 됨. 조인 애트리뷰트 두 번 모두 나옴
FROM 테이블명1 JOIN 테이블명2 ON 테이블명1.조인 애트리뷰트 = 테이블명2.조인 애트리뷰트
//2. 조인 애트리뷰트 이름이 같아야 함. 조인 애트리뷰트 한번만 나옴
FROM 테이블명1 JOIN 테이블명2 USING(조인 애트리뷰트)
//3. 자연 조인. 조인 애트리뷰트 한번만 나옴
FROM 테이블명1 NATURAL JOIN 테이블명2SELECT t1.column1, t1.column2, t2.column1, t2.column2
FROM 테이블명 t1 JOIN 테이블명 t2 ON 조인 조건
SELECT t1.SNO, t1.SNAME, t2.SNO, t2.SNAME
FROM 학생 테이블명 t1 JOIN 학생 테이블명 t2 ON t1.DEPT = t2.DEPT
WHERE t1.SNO < t2.SNO
//위의 예시에서 테이블명은 동일한 테이블을 나타내며,
//t1과 t2는 테이블의 별명(alias)이라고 불리는 것으로, 각각의 테이블을 구분하기 위해 사용됩니다
//예를 들어, "같은 학과 학생들의 쌍으로 검색하되,
//첫 번째 학번은 두 번째 학번보다 작게"하는 경우에는 다음과 같이 SQL 검색문을 작성할 수 있습니다:(9) 집계 함수를 이용한 검색
- 집계 함수의 결괏값은 하나이다.
- SQL은 집계 함수 또는 열 함수를 제공하고, COUNT, SUM, AVG, MAX, MIN이 있다. -> 한 열의 값 집합을 적용해서 다음과 같은 결과 생성
- COUNT(): 특정 컬럼의 개수를 세는 함수로, NULL 값을 제외하고 개수를 반환합니다.
- SUM(): 특정 컬럼의 합을 계산하는 함수로, NULL 값을 제외하고 합을 반환합니다.
- AVG(): 특정 컬럼의 평균을 계산하는 함수로, NULL 값을 제외하고 평균을 반환합니다.
- MAX(): 특정 컬럼의 최댓값을 찾는 함수로, NULL 값을 제외하고 최댓값을 반환합니다.
- MIN(): 특정 컬럼의 최솟값을 찾는 함수로, NULL 값을 제외하고 최솟값을 반환합니다
- SUM과 AVG는 수치 값에만 적용됩니다.(숫자형 데이터에서만 ㄱㄴ)
- 주로 GROUP BY 절과 함께 사용되어 그룹 단위로 데이터를 집계하고 분석하는데 사용됩니다. 주요한 SQL 집계 함수들은 다음과 같습니다:
- 질의문: 학생 테이블에 학생 수가 얼마인가를 검색하라.
- 질의문: 학번이 300인 학생이 등록한 과목은 몇 개인가?
- 질의문: 과목 'C413'에 대한 중간 성적의 평균은 얼마인가?
그룹화된 데이터를 집계함수를 이용해서 통계적인 결과를 얻을 수 있습니다.
그룹별로 집계 함수 적용함 !! HAVING을 통해 조건에 만족하는 것만 남겨서 그룹 내의 투플 개수 조절 !!!
각 그룹별로 평균, 최댓값 등등 ,,
각 그룹별로 개수가 3개 이상이어야 하면!! GROUP BY(그룹화할 열) HAVING COUNT(*)>=3
(10) GROUP BY를 이용한 검색
- 질의문: 과목별 기말 성적의 평균을 검색하라.
(11) HAVING을 사용한 검색-(10)과 연결되는 내용 !!!
- 질의문: 3명 이상 등록한 과목의 기말 평균 성적을 검색하라.
(12) 부속 질의문을 사용한 검색(WHERE 절에서!!)
//단일 값 비교:
SELECT column1, column2
FROM table1
WHERE column3 = (SELECT column3 FROM table2 WHERE condition);
//다중 값 비교: WHERE 절에는 두 테이블을 연결시킬 수 있는 조인 애트리뷰트가 존재해야 함!!!
SELECT column1, column2
FROM table1
WHERE column3 IN (SELECT column3 FROM table2 WHERE condition);
//부정 연산자 사용
SELECT column1, column2
FROM table1
WHERE column3 NOT IN (SELECT column3 FROM table2 WHERE condition);
// 서브 쿼리의 결과를 조건식으로 사용
SELECT column1, column2
FROM table1
WHERE column3 > (SELECT AVG(column3) FROM table2 WHERE condition)
//EXISTS절 사용
SELECT column1, column2
FROM table1
WHERE EXISTS (SELECT column3 FROM table2 WHERE condition)- ORDER BY는 메인 질의문에서만 사용하고, 부속 질의문에서는 사용하지 않습니다. -> 중첩 질의문에서는 주지 않음
- 질의문: 과목 번호 'C413' 등록한 학생 이름을 검색하라. (IN)
- 질의문: 과목 번호 'C413' 등록하지 않은 학생 이름을 검색하라. (NOT IN)
- 질의문: 학생 '정기태'와 같은 학과에 속하는 학생의 이름과 학과를 검색하라. (=) 어려워...
- 질의문: 등록 테이블에서 학번이 500인 학생의 모든 기말 성적보다 좋은 학기말 성적을 받은 학생의 학번과 과목번호를 검색하라. (> ALL)
(13) LIKE를 사용하는 검색
- LIKE 프레디킷은 서브 스트링 패턴을 비교하는 비교 연산자로 사용됩니다.
- 문자열 패턴을 기반으로 검색하는 데 사용되는 연산자입니다.
- %와 _ 와일드카드 문자를 사용하여 패턴을 지정할 수 있습니다.
- %는 0개 이상의 문자를 대체하고, _는 정확히 한 개의 문자를 대체합니다.
- %는 서브 스트링 패턴을 명세하는 것으로 'C'로 시작하라 -> C%
- LIKE 'S_ _' = S로 시작하는 세 문자 스트링
- LIKE '%S_ _' = 스트링 끝에서 세 번째가 'S'인 스트링
- LIKE '%S%' = 'S'가 포함된 스트링
- 질의문: 과목 번호가 C로 시작하는 과목의 과목 번호와 과목이름을 검색하라.
- 문자열이니깐 LIKE ' ' 작은 따옴표 붙여줘야 한다.
(14) NULL을 사용한 검색
- 검색 조건 속에 명세할 때 "열_이름 IS [NOT] NULL"의 형식만 허용
- 열 이름 = NULL의 형식은 불법적인 것!!!(시험 문제 )
- 다음 중 틀린 표현을 찾으세요!
- NULL은 누락 정보로서 값은 있지만 모르는 값이나 해당되지 않는 값 또는 의도적으로 유보한 값을 나타냄
- 논리 값으로 보면 NULL은 미정값(unknown)
- 질의문: 학과가 NULL인 학생의 학번과 이름을 검색하라.
Year = NULL (불법)
Year != NULL (불법)
Year > 3
Year <=3(15) EXISTS를 사용하는 검색 - 존재하면 T, 존재하지 않으면 F
검색테이블을 T1, 연결테이블을 T2라고 해보겠다.
SELECT T1.(가져올 열)
FROM T1
WHERE EXITS(
SELECT *
FROM T2
WHERE T1.조인애트리뷰트 = T2.조인애트리뷰트 AND 조건식);
//T1과 T2의 공통되는 부분이 있으면서 조건을 만족하는 T2의 레코드가 하나라도 있다면 트루를 반환해서
//T1에서 열을 가져올 수 있습니다.
//연결테이블과 우리가 검색해야 하는 테이블은 조인애트리뷰트 가지고 있다.(외래키-기본키) 이걸 통해서 연결!
//두개 연결할 수 있는 공통점도 있고 조건도 만족하는 T2가 존재하면 우리가 원하는 값 가져올 수 있음!
- 서브쿼리(subquery)의 결과가 존재하는지 여부를 검사하여, 결과가 존재하면 참(true)을 반환하고, 결과가 없으면 거짓(false)을 반환하는 SQL 연산자
- 서브쿼리는 EXISTS 연산자 내부에 위치한 서브쿼리로, 조건에 따라 결과를 반환합니다.
- 만약 서브쿼리의 결과가 존재하는 경우에는 WHERE 절의 조건이 참(true)이 되어 해당 테이블의 레코드가 반환되고, 서브쿼리의 결과가 없는 경우에는 WHERE 절의 조건이 거짓(false)이 되어 해당 테이블의 레코드가 반환되지 않습니다.-> EXISTS(SELECT * FROM) 검색문 실행 후 그 결과가 공집합이 아니면 참, 공집합이면 거짓
- EXISTS( ) ( ) 안에 조인하는 조건은 들어가있지만, 결과물은 조인한 것이 아님. 조인은 FROM 에 테이블 두 개가 와야 됩니다.
- 질의문: 과목 'C413'에 등록한 학생의 이름을 검색하라.
- 질의문: 과목 'C413'에 등록하지 않은 학생의 이름을 검색하라.
(16) UNION이 관련된 검색
- 일반 집합론의 합집합과 같다.
- UNION 사용하면 결과 테이블에서 중복되는 투플은 제거됨
- 두 개의 WHERE문 합치기 가능
- 질의문: 3학년이거나 또는 과목 'C324'에 등록한 학생의 학번을 검색하라.
SELECT column1, column2 FROM table1
UNION
SELECT column1, column2 FROM table2;
각자 테이블에서 열을 골랐어요. 그 다음에 합집합하는 것임.
따라서 도메인이 같아야 되겠지.3. 데이타 갱신
- 기존 레코드 열의 값을 변경하기 위해서 UPDATE 명령문 사용
- 새로 변경되는 값은 산술식이나 NULL(허용이 되는 경우에만)될 수 있다.
- WHERE절이 명세되면 조건을 만족하는 모든 레코드들이 SET절에 지시된 대로 변경
//일반적인 형식
UPDATE 테이블
SET {열 이름 = 산술식}'+
[WHERE 조건];
UPDATE 테이블명
SET 열1 = 값1, 열2 = 값2, ...
WHERE 조건;
UPDATE students
SET age = 25
WHERE student_id = 1001;(1) 하나의 레코드 변경
- 질의문: 학번이 300인 학생의 학년을 2로 변경하라.
(2) 복수의 레코드 변경
- 질의문: '컴퓨터'과 과목의 학점을 1학점씩 증가시켜라.
4. 데이타 삽입
- 기존 테이블에 행을 삽입할 경우 INSERT 문 사용
- 열의 값과 열의 이름은 그 명세된 순서대로 일대일 대응
//레코드의 직접 삽입
INSERT
INTO 테이블명 (열1, 열2, ...) //열_이름_리스트
VALUES (값1, 값2, ...); //열_값_리스트
//부속질의문을 이용한 레코드 삽입
INSERT
INTO 테이블명 (열1, 열2, ...) //열_이름_리스트
SELECT문;
(1) 레코드의 직접 삽입
- 질의문: 학번: 600, 이름: '박상철', 학년:1, 학과: '컴퓨터'인 학생을 삽입하라.
INSERT
INTO STUDENT(Sno, Sname, Year, Dept)
VALUES(600, '박상철', 1, '컴퓨터');
//위와 같은 결과 나옵니다.
INSERT
INTO STUDENT
VALUES(600, '박상철', 1, '컴퓨터');
//만일 학과 이름을 모른다면 '학과' 해당하는 난을 공백으로 남겨두기 -> NULL 값으로 취급됨
INSERT
INTO STUDENT(Sno, Sname, Year)
VALUES(600, '박상철', 1);(2) 부속 질의문을 이용한 레코드 삽입
- 질의문: 학생 테이블에서 '컴퓨터'과 학생의 학번, 이름, 학년을 검색하여 테이블 컴퓨터에 삽입하라.
INSERT
INTO COMPUTER(Sno, Sname, Year)
SELECT Sno, Sname, Year
FROM STUDENT
WHERE Dept='컴퓨터';
5. 데이타의 삭제(DELETE)
- 기본적으로 투플을 대상으로 한다.
- DELETE문은 WHERE절의 조건을 만족하는 레코드를 모두 삭제한다.
- 만일 WHERE절이 없으면 이 테이블은 투플이 모두 삭제 된 빈 테이블로 된다.
DELETE
FROM 테이블
[WHERE 조건];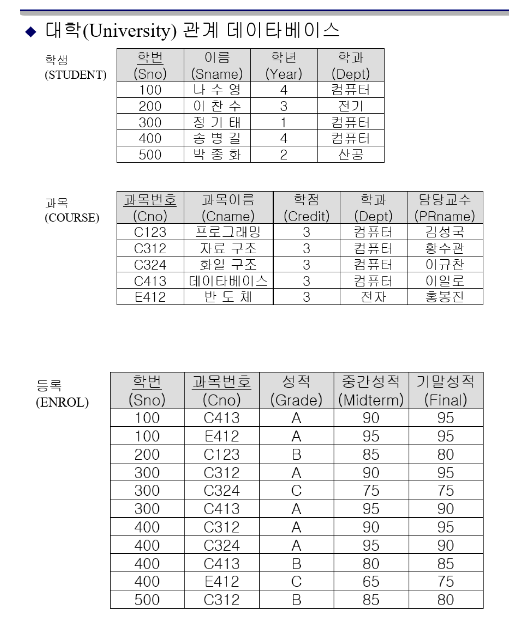
(1) 하나의 레코드 삭제 -> 참조 무결성 문제 발생 가능
- 질의문: 학번 100인 학생을 삭제하라.
- 만일 학번(Sno)를 외래키로 가지고 있는 테이블이 있다면 그 테이블에서도 같은 삭제 연산이 수행되어야 한다. <- 참조 무결성을 유지하기 위해서!!!
- 등록(ENROL) 테이블이 학번(Sno)을 외래키로 가지고 있으므로 등록 테이블로부터 학번이 100인 레코드를 전부 삭제시켜야 된다.
(2) 복수의 레코드 삭제
- 질의문: 등록 테이블이 모든 행을 삭제해라
- 이 삭제문의 실행 결과로서 등록 테이블은 투플이 없는 빈 테이블로 된다.
- 테이블 자체는 계속 데이터베이스에 남아 있는 것이지 없어지는 것 X -> 테이블의 제거(DROP)과 다르다.
(3) 부속 질의문을 사용한 삭제
- 질의문: 과목 'C413'의 기말 성적인 60점 미만인 '컴퓨터'과 학생을 등록 테이블에서 삭제하라
SQL 뷰(VIEW)
1. SQL 뷰의 정의
- 뷰는 기본적으로 다른 테이블로부터 유도된 이름을 가진 가상 테이블
- 외부 스키마는 뷰와 기본 테이블들의 정의로 구성됨
-
기본 테이블을 들여다보는 '유리창'(window) -> 동적임
- 기본 테이블은 물리적으로 구현되어 데이타가 실제로 저장되지만 뷰는 물리적 구현 X
- 뷰의 정의만 시스템 내에 저장하여 두었다가 필요시 실행 시간에 테이블을 구축(카탈로그(SYSVIEWS)에 SELECT-FROM-WHERE의 형태로 저장됨)
- 데이타 검색에 있어서 시스템은 일반 사용자에게 뷰와 기본 테이블 사이에 아무런 차이가 없게 만들어 준다.
- 뷰에 대한 데이타의 갱신 연산에만 약간의 차이가 있다.
- 뷰는 궁극적으로 기본 테이블로부터 유도 BUT 정의된 뷰가 또 다른 뷰를 정의할 때 기초 가능 -> 이것도 기본 테이블을 기초로 함 !!! 새로 정의된 뷰가 기초한 뷰도 기본 테이블에 기초 두었으니깐!!
- 뷰에 대한 삽입, 수정, 삭제 연산은 실제로 기본 테이블에 수행되어 결과적으로 기본 테이블이 변경됨
- 기본 테이블 변경된다고 뷰가 변경되지는 않음 !!!
2. 뷰의 생성
CREATE VIEW 뷰 이름[(열_이름_리스트)]
AS SELECT문
[WITH CHECK OPTION];
//'CSTUDENT'뷰
//STUDENT 테이블의 '컴퓨터'과 학생들로 구성된 컴퓨터과 학생
CREATE VIEW CSTUDENT(Sno, Sname, Year)
AS SELECT Sno, Sname, Year
FROM STUDENT
WHERE Dept='컴퓨터'
WITH CHECK OPTION;
//위의 정의문과 동일
CREATE VIEW CSTUDENT
AS SELECT Sno, Sname, Year
FROM STUDENT
WHERE Dept='컴퓨터'
WITH CHECK OPTION;- AS SELECT문은 일반 검색문과 같지만 UNION, ORDER BY 사용 X
-
WITH CHECK OPTION : 갱신이나 삽입 연산 시 뷰 정의 조건을 검사 -> 뷰의 정의 조건(Dept='컴퓨터')를 위반하면 실행이 거부된다는 것을 명세
- 위의 정의문 실행하면 학번(Sno), 이름(Sname), 학년(Year)등 3열의 이름을 가진 CSTUDENT 뷰 만들어짐

기본 테이블 STUDENT의 CSTUDENT 뷰
- 뷰 정의문에서 열 이름이 명세되지 않으면 AS SELECT문에 나오는 열의 이름을 그대로 상속받음( 기본테이블이 AS SELECT에 들어가니깐 !!)
- 정의하는 뷰에 집계 함수가 들어가서 상속 X, 상속받았을 때 열의 이름이 중복되는 경우 뷰의 정의문에 새로운 열의 이름 명세해야 함
//AS SELECT : 열의 이름 상속
상속이 불가능한 경우나 열 이름이 중복될 경우 반드시 열 이름 명세
//기본테이블인 STUDENT에서 열이름 상속받을랬는데 DEPSIZE 뷰 정의문에서 두 번째 열은 집계 함수
//-> 열 이름 상속받을 수 없어서 Size로 명세 -> 기본테이블의 통계적 요약 테이블
CREATE VIEW DEPTSIZE(Dept, Size)
AS SELECT Dept, COUNT(*)
FROM STUDENT
GROUP BY Dept;
CREATE VIEW DEPTSIZE
AS SELECT Dept, COUNT(*) AS SIZE
FROM STUDENT
GROUP BY Dept;
- 두 개 이상 테이블 조인
CREATE VIEW HONOR(Sname, Dept, Grade)
AS SELECT STUDENT.Sname, STUDENT.Dept, ENROL.Final
FROM STUDENT, ENROL
WHERE STUDENT.Sno = ENROL.Sno AND ENROL.Final > 90;- 정의된 뷰를 이용하여 또 다른 뷰를 정의
CREATE VIEW COMHONOR
AS SELECT Sname
FROM HONOR
WHERE Dept = '컴퓨터';3. 뷰의 제거
- RESTRICT: 다른 곳에서 참조되고 있지 않는 한 데이타베이스에서 제거
- CASCADE: 이 뷰가 사용된 다른 모든 뷰나 제약 조건이 함께 제거
- 실제로 뷰에 대한 시스템 테이블에서 DEPSIZE에 대한 뷰의 정의문 제거
- 시스템 테이블? 시스템 테이블은 카탈로그(catalog)에 저장
DROP VIEW 뷰_이름 { RESTRICT | CASCADE };
//DEPSIZE가 다른 곳에서 참조되고 있지 않으면 데이타베이스에서 제거되어 없어짐
DROP VIEW DEPTSIZE RESTRICT;
//해당 뷰, 이 뷰가 사용된 다른 모든 뷰나 제약 조건 함께 제거
DROP VIEW DEPTSIZE CASCADE;4. 뷰의 조작 연산
- 기본 테이블에 사용 가능한 검색(SELECT)문은 모두 뷰에 사용 가능
-
변경(삽입, 삭제, 갱신) 연산은 제약
- 뷰에서 이론적으로는 변경이 가능하지만 실제로 변경이 불가능한 뷰와 변경이 가능한 뷰, 그리고 변경할 수 없는 뷰로 나뉩니다.
- 뷰는 제한적인 갱신만 가능하며, 뷰에 대한 변경이 가능하려면 먼저 그 뷰는 어느 한 기본 테이블의 행과 열의 부분집합으로만 정의되어야 함
- 이론적으로 변경이 가능하지만 실제로 변경이 불가능한 뷰
- 뷰를 구성하는 기본 테이블의 구조가 변경된 경우
- 뷰를 구성하는 기본 테이블의 이름이 변경된 경우
- 뷰를 참조하는 다른 뷰나 인덱스 등이 존재하는 경우
- 변경이 가능한 뷰
- 뷰를 구성하는 기본 테이블의 데이터가 변경되는 경우
- 뷰를 구성하는 기본 테이블의 인덱스가 변경되는 경우
- 변경할 수 없는 뷰(이러한 형태로 만들 수는 있는데 변경은 안 되는 것임 !!)
- 뷰를 구성하는 기본 테이블의 제약 조건이 변경되는 경우
- 뷰를 구성하는 기본 테이블의 컬럼이 변경되는 경우
- 뷰의 SELECT 문에 사용되는 함수나 연산자 등이 변경되는 경우
- 뷰의 열이나 상수나 산술 연산자 또는 함수가 사용된 산술 식으로 만들어짐
- 집계 함수가 관련되어 정의된 뷰 = 통계적 요약 뷰
- DISTINCT, GROUP BY 또는 HAVING이 사용되어 정의된 뷰
- 두 개 이상의 테이블이 관련되어 정의된 뷰 = 조인 뷰
- 변경할 수 없는 뷰를 기초로 정의된 뷰
5. 뷰의 장단점
(1) 뷰의 장점
- 뷰는 데이터의 논리적 독립성을 어느 정도 제공 (확장, 구조 변경) -> 뷰가 정의된 기본 테이블이 확장 or 뷰가 속한 데이타베이스의 테이블이 늘어나도 기존의 뷰는 영향 받지 x -> 데이터의 확장성과 구조 변경을 용이하게 합니다.
- 데이타의 접근을 제어(보안) -> 뷰를 통해서만 데이타 접근하면 뷰에 나타나지 않은 데이타 안전하게 보호 가능
- 사용자의 데이타 관리를 단순화 -> 필요한 데이타만 뷰로 정의해서 처리하므로 관리 용이, 질의문 간단
- 여러 사용자에 다양한 데이타 요구를 지원 -> 뷰를 통해 여러 사용자에게 다양한 데이터 요구를 지원할 수 있습니다. 뷰는 각 사용자의 요구사항에 따라 데이터베이스를 다양하게 볼 수 있도록 도와줍니다.
(2) 뷰의 단점
- 정의를 변경할 수 없음삽입, 삭제, 갱신 연산에 제한이 많음
삽입 SQL
1. SQL의 이중 모드 원리
- SQL은 터미널을 통해 대화식으로 직접 사용할 수 있는 질의어인 동시에 범용 프로그래밍 언어로 작성된 응용 프로그램 속에 삽입시켜 사용할 수도 있다.
- 삽입 SQL은 이중 모드 원리를 가지고 있다.
** 이중 모드 원리? 터미널에서 대화식으로 사용할 수 있는 모든 SQL 문을 응용 프로그램에서도 사용 가능하다는 것
2. 삽입 SQL을 포함하는 응용 프로그램의 특징
- 삽입 SQL문은 명령문 앞에 'EXEC SQL'을 붙임 -> 다른 호스트 언어의 명령문과 구분삽입 SQL문 끝은 세미콜론(;)과 같은 특별한 종료 심벌을 붙여 표시
- 삽입 SQL 실행문은 호스트 언어 실행문이 사용되는 곳이면 어디나 나타날 수 있음
- 대화식 SQL과 달리 삽입 SQL문에는 실행문, 비 실행문이 있는데 DECLARE CURSOR, BEGIN, END, DECLARE SECTION과 같은 SQL문이 비 실행문.
- 삽입 SQL문은 호스트 변수 포함할 수 있으며, 앞에 콜론(:)을 붙임
- 호스트 변수는 검색 결과를 저장하는 장소를 나타내기 위해 INTO절에 나타남
- SQL문에서 사용할 호스트 변수는 사용하기 전 반드시 삽입 SQL 선언부 BEGIN/END DECLARE SECTION 속에서 선언되어야 함
- 모든 삽입 SQL 프로그램은 SQLSTATE라는 5문자로 된 스트링 타입의 호스트 변수를 포함( 실행상태 표시가 SQLSTATE 변수를 통해 프로그램에 전달됨. -> "00000"이면 SQL문 성공, "00000"이 아니면 경고 또는 에러)
- 호스트 변수와 대응하는 열의 데이타 타입은 일치
- 호스트 변수와 열의 이름은 같아도 됨(호스트 변수 앞에 콜론(:) 붙여서 구분 하니깐)
//C/C++ 언어와 SQL을 혼합하여 사용하는 응용 프로그램의 예시
//테이블에 있는 레코드의 정보를 SQL문을 통해서 가져와 -> 그것을 C++ 변수값에 저장해서 사용!!
//EXEC SQL은 SQL 문장을 나타내는 것
// STUDENT 테이블에서 Sno가 100인 레코드를 선택하고,
//해당 레코드의 Sname과 Dept 값을 sname과 dept 변수에 저장하는 코드입니다.
//이후 SQLSTATE 변수를 사용하여 SQL 문장의 실행 결과를 확인
//선언 섹션 시작
EXEC SQL BEGIN DECLARE SECTION;
// SQL 문장에 사용되는 변수들을 선언하기 위한 섹션입니다.
//이 예시에서는 sno, sname, dept, SQLSTATE 변수를 선언
int sno; char sname[21]; char dept[7]; char SQLSTATE[6];
//선언 섹션 종료
EXEC SQL END DECLARE SECTION;
//sno=100;은 sno 변수에 100을 할당하는 코드입니다.
//이렇게 함으로써 SELECT 문에서 :sno 매개 변수를 사용할 수 있습니다.
sno=100;
//STUDENT 테이블에서 Sno가 :sno에 해당하는 레코드를 선택하고,
//해당 레코드의 Sname과 Dept 값을 :sname과 :dept에 저장하는 SELECT 문입니다.
EXEC SQL SELECT Sname, Dept
INTO :sname, :dept
FROM STUDENT
WHERE Sno=:sno;
//SQLSTATE 변수를 사용하여 SQL 문장의 실행 결과를 확인합니다.
//SQLSTATE 값이 '00000'인 경우는 SQL 문장이 성공적으로 실행된 경우를 나타냅니다.
//이 경우는 아무 작업도 하지 않고 넘어갑니다.
//그렇지 않은 경우(ELSE)에는 해당 문장에서 오류가 발생했음을 나타낼 수 있습니다.
IF(SQLSTATE='00000') ;
.........
ELSE
- EXEC SQL BEGIN DECLARE SECTION;은 선언 섹션을 시작하고, EXEC SQL END DECLARE SECTION;은 선언 섹션을 종료하는 것을 나타냅니다.
- 섹션에서 선언된 변수들은 SQL 문장에서 사용되는 바인딩 변수로 사용됩니다.
- EXEC SQL BEGIN DECLARE SECTION;과 EXEC SQL END DECLARE SECTION;은 SQL 문장을 실행하기 전에 필요한 변수들을 선언하는 구간을 표시하는 역할을 합니다.
- 이 구간은 해당 섹션 내에서 변수들이 정의되고, 선언된 변수들은 이후의 SQL 문장에서 사용될 수 있습니다.
3. 커서
- 삽입 SQL 연산들 중 SELECT 명령문 주의 필요
- SELECT에 의한 검색 결과는 일반적으로 몇 개의 투플로 구성되는 테이블
- 호스트 언어는 한 번에 하나의 레코드만 취급. 몇 개의 레코드로 된 집합은 취급 X
- SQL의 레코드 집합 단위 처리와 호스트 언어의 개별 레코드 단위 처리 사이에 교량 시설 요구 "커서"
- 커서는 응용 프로그램의 삽입 SQL에만 사용되는 새로운 객체
- 집합에 있는 각 레코드들을 한 번에 하나씩 지시할 수 있게 해서 그 레코드 집합 전체를 처리할 수 있도록 함
- SELECT문과 호스트 프로그램 사이를 연결
- SELECT 문으로 검색되는 여러 개의 레코드(투플)를 대상으로 정의됨
- 활동 세트: SELECT문으로 검색된 레코드 집합
- 실행 시에는 활동 세트에 있는 레코드 하나를 지시함
4. 커서가 필요 없는 데이타 연산
- WHERE절을 만족하는 레코드가 있어야 SQLSTATE 변수의 값이 "00000"이 됨
- WHRER절을 만족하는 레코드 없으면 SQLSTATE 변수의 값은 "02000"이 됨
(1) 단일 레코드 검색
- (검색된 테이블이 한 개 이하의 행만을 가지는 SELECT문)
- 질의문: 학번이 호스트 변수 :sno로 주어지는 학생의 이름과 학과를 검색하라.
(2) 갱신
- 과목 'C413'에 등록한 학생의 기말 성적을 호스트 변수 :new 값만큼 증가시켜라.
(3) 삭제
- 호스트 변수 :sno의 값을 가진 학생의 모든 등록(ENROL) 레코드를 삭제하라.(구분 필요x)
(4) 삽입
- 호스트 변수 :sno, :sname, :dept들로 값이 주어지는 학생 레코드 하나를 학생 테이블에 삽입하라.
4. 커서를 이용하는 데이타 조작
(1) 복수 레코드 검색

- 여러 개의 레코드를 검색하는 삽입 SELECT문
- 호스트 변수 :dept 값과 같은 학과(Dept)에 속한 학생(학번, 이름, 학년)의 레코드 전부를 검색
- DECLARE CURSOR문은 커서와 커서 뒤에 나오는 SELECT문을 연결시키는 데 사용(C1이 FOR 다음에 나오는 SELECT문과 연관시킴)
- SELECT문은 CURSOR가 개방될 때 실행됨(open)
- 커서와 관련된 명령은 OPEN, FETCH, CLOSE가 있음

- 커서가 다음으로 이동할 때, 커서는 활동 세트에서 다음 레코드로 이동하며, 이동한 레코드를 새로운 활동 세트의 일부로 간주합니다. 따라서, 커서가 이동할 때마다 활동 세트의 레코드 수는 하나씩 줄어들게 됩니다. 커서가 마지막 레코드를 가리킬 때 활동 세트는 비어있게 됩니다.
- 결과 세트는 조건을 만족하는 모든 레코드의 집합입니다. 쿼리를 실행하면 결과 세트에는 조건을 만족하는 모든 레코드가 포함되며, 커서를 통해 하나씩 읽어나가는 작업을 수행할 수 있습니다.
- 따라서, 커서는 현재 가리키고 있는 레코드와 그 밑에 있는 일부 레코드들을 활동 세트로 간주하며, 결과 세트는 조건을 만족하는 모든 레코드의 집합입니다.
(2) 변경
- 커서 C1이 가리키고 있는 특정 레코드 CURRENT OF C1;을 변경

(3) 삭제
- 커서 C1이 가리키고 있는 특정 레코드 CURRENT OF C1;을 삭제

퀴즈(pdf 35~)
- 뷰는 기본 테이블로부터 유도 되며, 검색 연산 동일하다.
- 논리적 독립성 제공
'데이터베이스기초' 카테고리의 다른 글
| [데이타베이스기초] 5장 관계 대수 (0) | 2023.04.17 |
|---|---|
| [데이타베이스기초] 4장 관계 데이타베이스 (0) | 2023.04.17 |
| [데이타베이스기초] 데이타베이스 시스템의 구성 (0) | 2023.04.17 |
| [데이타베이스기초] 데이타베이스 관리 시스템 (0) | 2023.04.16 |
| [데이타베이스기초] 정보 환경 (0) | 2023.04.16 |


